Een goed ontworpen en geïmplementeerde database is cruciaal voor de prestaties, schaalbaarheid, flexibiliteit en beveiliging van applicaties en informatiesystemen. In dit artikel zullen we het vooral hebben over het belang van een goed databaseontwerp en de implementatie ervan.
Databases zijn nog steeds erg belangrijk en vaak minder populair dan de applicaties die hierop worden ontwikkeld. Toch is de database nog steeds een stabiele factor en ontwikkelingen op het gebied van snelheid, beveiliging as ook stabiliteit blijft zich continu verbeteren. Of het hier nu gaat om DB2, Microsoft SQL-Server, Oracle, Sybase of MySQL iedere database heeft zo zijn eigen kenmerken, maar zijn vaak qua structuur nog steeds Relationeel (RDBMS). Ze kunnen grote aantallen gegevens verwerken op verschillende besturingssystemen als Unix, Linux of Windows Server. Maar worden ook vaak voor cloud-oplossingen of specifieke toepassingen gebruikt.
Toch zien we dat een goed databaseontwerp van enorm belang is voor de performance maar ook de gegevensintegriteit van alle data. Een verkeerd gekozen implementatie hiervan kan desastreuze gevolgen hebben. Maar wat is dan een goed ontwerp en hoe pak je dit aan? Wat zijn de do’s en don’ts voor een goed databaseontwerp en ondersteunt onze applicatie software dit wel. In dit artikel zullen we je meer informatie geven over dit onderwerp.
Waarom is een goed databaseontwerp nodig?
Wanneer we het hebben over een goed databaseontwerp dan zal dit in veel gevallen zijn ontstaan door een “logisch nadenken” van een database administrator (DBA). Ik ben in de praktijk regelmatig tegen projecten aan gelopen waar een goede analyse en methodische aanpak compleet ontbrak en de database was opgezet door een “ervaren” DBA. Maar is dit nu een goed databaseontwerp?
Hier wordt dus direct de eerste grote fout gemaakt. Vooral door techniek gedreven organisaties zien de database als een externe opslagplaats en minder als een goede gestructureerde afspiegeling van de informatie die zou moeten worden vastgelegd op een eenduidige en gestructureerde manier.
Het gebruik van een methodiek
Een database en in het bijzonder een RDBMS (Relationele database) is een structuur die alleen optimaal kan worden ingericht als je ook minimaal een goede informatieanalyse en functioneel ontwerp hebt gemaakt.
Conceptueel ontwerp
Methodes als ER-modelling of verschillende dialecten van NIAM zijn hier bij uitstek de basis voor. Het resultaat hiervan is dat er uiteindelijk een conceptueel model wordt gemaakt dat op een eenduidige manier kan worden afgestemd met de gebruikers van een toekomstig informatiesysteem.
De communicatie is hierbij niet van technische aard en dus worden alle belangrijke aspecten van de informatie die moet worden vastgelegd meegenomen. Een goede analist / ontwerper weet de juiste vragen te stellen of voorbeelden te reproduceren voor het nieuwe systeem.
Voorbeelden van vragen die ingewikkelder zijn bepalen ook alle soorten van beperkingen die zouden kunnen ontstaan. Een analyse methode als NIAM zal hiervoor concrete voorbeelden gebruiken waar de bevolking van beweringen worden gevalideerd. Later zullen deze in verschillende soorten van constraints worden geïmplementeerd.
Technisch ontwerp
Wanneer er een goed conceptueel (logisch) ontwerp is gemaakt is de volgende stap het omzetten van dit ontwerp naar een technisch ontwerp. Het technisch ontwerp zal dan vooral de implementatie zijn van dit relationele model naar een specifiek RDBMS toe.
De term functioneel ontwerp heb ik hier bewust niet gebruikt, aangezien veel organisaties dit zien als een ontwerp waar de bedrijfsprocessen in worden beschreven en waar dan vaak een ontwerp is toegevoegd welke niet conceptueel is maar fysiek.
Vaak worden er tools gebruikt die dit automatisch kunnen uitvoeren met alle mogelijkheden van het relationeel database management systeem (RDBMS) zelf.
Maar hier ontstaat vaak een tweede fout die wordt gemaakt bij de implementatie van het technische ontwerp.
Implementatie van het technisch ontwerp
Wanneer je een goed conceptueel ontwerp hebt voor je database en je hebt een technisch ontwerp hieruit aangemaakt zie je vaak dat er op verschillende manieren de impplementatie wordt uitgevoerd.
Business rules
De business rules die je vanuit een technisch ontwerp kunt implementeren zijn op verschillende manieren te implementeren. De grootste fout die je in de praktijk ziet gebeuren is dat deze niet in de database zelf worden afgehandeld, maar in de applicatie.
Het gevaar welke hierdoor ontstaat, is dat de database zelf NIET bewaakt wordt voor het vastleggen van ongeldige informatie. Daarom is het belangrijk om altijd alle business rules op de database zelf te implementeren en deze voor de gebruiksvriendelijkheid te reproduceren naar je client applicatie.
Data-integriteit en consistentie
Om beter te begrijpen welke mogelijkheden er zijn om alle constraints en business rules in je database vast te leggen zullen we hier een aantal standaard elementen bespreken die in ieder professioneel RDBMS is terug te vinden.
Constraints:
Wanneer we naar het technisch ontwerp kijken van het technisch ontwerp dan zijn er altijd een aantal basis uniciteitsregels die vrij eenvoudig kunnen worden afgehandeld.
Unieke constraints als primaire key: De unieke sleutel voor een tabel is met de unique constraint of primairy key op ieder DBMS te implementeren. Hierdoor wordt vastgelegd welke velden of combinatie van velden uniek is in een tabel.
Voorbeeld:
CREATE TABLE Klanten (
KlantID INT NOT NULL,
Voornaam VARCHAR(50),
Achternaam VARCHAR(50),
Email VARCHAR(100),
PRIMARY KEY (KlantID)
);
In dit voorbeeld wordt KlantID als primaire sleutel voor de Klanten tabel ingesteld, wat betekent dat elke klant een uniek KlantID moet hebben.
Wanneer er sprake is van meer combinaties van informatie dan kan de alternate key constraint worden gebruikt. Deze constraints kunnen vrij eenvoudig met de volgende syntax worden aangemaakt.
CREATE TABLE Werknemers (
WerknemerID INT NOT NULL PRIMARY KEY,
SSN CHAR(9) NOT NULL,
Voornaam VARCHAR(50),
Achternaam VARCHAR(50),
UNIQUE (SSN)
);
In dit voorbeeld is WerknemerID de primaire sleutel van de Werknemers tabel, wat betekent dat elke werknemer een uniek WerknemerID moet hebben. Daarnaast is SSN (Social Security Number) gedefinieerd als een alternatieve sleutel met de UNIQUE constraint, wat aangeeft dat elke werknemer een uniek SSN moet hebben, maar SSN is niet de primaire sleutel van de tabel.
Je kunt ook een alternatieve sleutel op een bestaande tabel toevoegen met het ALTER TABLE commando, zoals in het volgende voorbeeld:
ALTER TABLE Werknemers
ADD UNIQUE (Email);
Dit commando voegt een unieke constraint toe aan de kolom Email, waardoor het een alternatieve sleutel wordt. Dit betekent dat elke waarde in de kolom Email uniek moet zijn over alle rijen in de Werknemers tabel.
CHECK Constraints: Hiermee kun je een voorwaarde opgeven waaraan de waarden in een kolom moeten voldoen. Bijvoorbeeld, een CHECK constraint kan worden gebruikt om te verzekeren dat een leeftijdskolom alleen positieve waarden bevat.
ALTER TABLE Werknemers
ADD CONSTRAINT chkLeeftijd CHECK (Leeftijd >= 18);
Foreign Keys:
Wanneer we verwijzende sleutels hebben binnen het ontwerp dan kunnen deze vrij eenvoudig als Foreign keys worden geimplementeerd. Een foreign key is dus een verwijzing naar een ander andere kolom in een tabel. Deze verwijzingen zijn gebaseerd op de unieke identificatie (primairy key) van de referentie.
Voorbeeld:
CREATE TABLE Klanten (
KlantID INT PRIMARY KEY,
Naam VARCHAR(100),
Email VARCHAR(100) );
CREATE TABLE Bestellingen (
BestellingID INT PRIMARY KEY,
BestelDatum DATE,
KlantID INT,
FOREIGN KEY (KlantID) REFERENCES Klanten(KlantID);
In dit voorbeeld:
- KlantID in de Klanten tabel is de primaire sleutel.
- KlantID in de Bestellingen tabel is de foreign key die verwijst naar KlantID in de Klanten tabel.
Dit zorgt ervoor dat elke Bestelling in de Bestellingen tabel geassocieerd is met een bestaande Klant in de Klanten tabel.
Belangrijk om te weten:
- Een tabel kan meerdere foreign keys hebben, afhankelijk van hoeveel relaties het heeft met andere tabellen.
- Een foreign key kan verwijzen naar de primaire sleutel of een unieke sleutel in de referentietabel.
- Wanneer een actie wordt uitgevoerd die de referentiële integriteit zou kunnen schenden (zoals het verwijderen van een rij in de Klanten tabel die wordt verwezen door een rij in de Bestellingen tabel), treden er constraint violations op, tenzij er cascade-acties of andere integriteitsregels zijn gedefinieerd.
Triggers:
Een trigger kan op een tabel of view worden gedefinieerd. Een trigger zal worden uitgevoerd wanneer er een insert, update of zelfs delete wordt uitgevoerd waarbij de tabel Een trigger is vooral handig voor de wat gecompliceerde business rules.
Voorbeeld van een Trigger:
Stel je hebt een Bestellingen tabel en een Voorraad tabel. Je wilt de voorraad automatisch bijwerken wanneer er een nieuwe bestelling wordt geplaatst. Je kunt een AFTER INSERT trigger op de Bestellingen tabel maken die het aantal producten in de Voorraad tabel vermindert op basis van de hoeveelheid van de geplaatste bestelling.
CREATE TRIGGER UpdateVoorraad
AFTER INSERT ON Bestellingen
FOR EACH ROW
BEGIN
UPDATE Voorraad
SET aantal = aantal – NEW.bestelde_hoeveelheid
WHERE productID = NEW.productID;
END;
In dit voorbeeld wordt de trigger UpdateVoorraad automatisch uitgevoerd na elke INSERT-operatie op de Bestellingen tabel. NEW.bestelde_hoeveelheid en NEW.productID verwijzen naar de waarden van de kolommen in de rij die net is ingevoegd in de Bestellingen tabel. De trigger past de Voorraad tabel aan door het aantal van het betreffende product te verminderen.
Aandachtspunten:
- Prestaties: Het onzorgvuldig gebruik van triggers kan leiden tot prestatieproblemen, vooral als ze complexe bewerkingen uitvoeren of worden uitgevoerd op tabellen met een hoog volume aan transacties.
- Complexiteit: Triggers kunnen de logica van een database complexer maken, wat het moeilijker maakt om de oorzaak van problemen te diagnosticeren, omdat de werking van triggers niet altijd duidelijk is vanuit de context van een applicatie die de database gebruikt.
- Onderhoud: Het onderhouden van triggers vereist zorgvuldige documentatie en beheer, vooral in grote databases met veel triggers.
Stored procedures
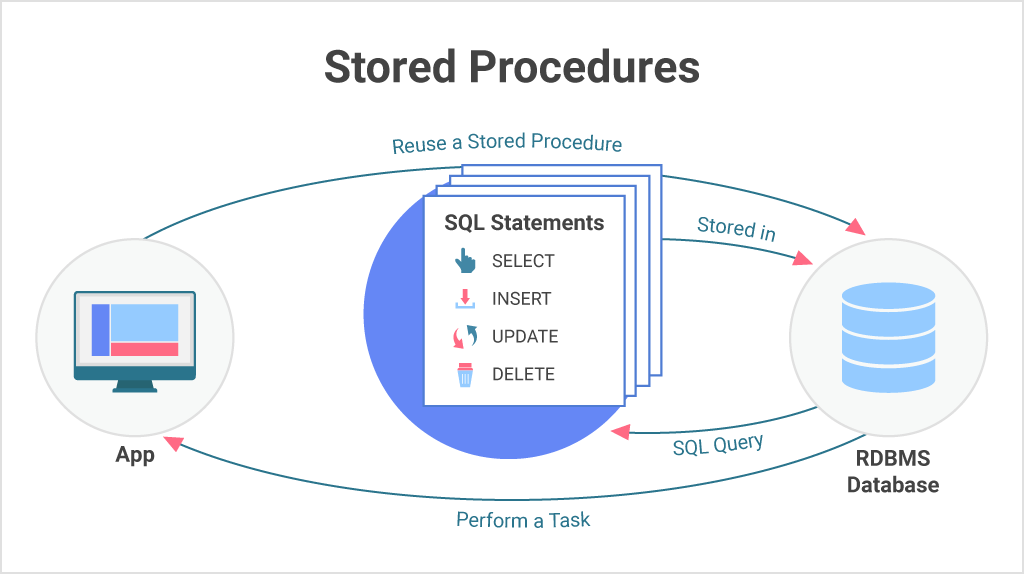
Een stored procedure is een gecompileerd stukje SQL code welke kan worden uitgevoerd om een datamanipulatie uit te voeren. Deze code is op voorhand geoptimaliseerd op basis van een gecompileerd query plan voor gebruik van de juiste indexen. Hierdoor snel en ook altijd minder netverkeer in TDS over de connectie van de client en server.
Een stored procedure zou eigenlijk de enige manier moeten zijn om de database te bewerken voor het inserten, updaten of wijzigen van informatie.
Het voordeel is dat een stored procedure ook kan worden geautoriseerd en de database consistentie kan bewaken (denk hierbij ook aan constraints die worden bewaakt).
Wel dient er een juist error afhandeling worden gedefinieerd vanuit de client. Voor elke mogelijke melding kan een user defined message worden aangemaakt die vanuit de connectie in de client kan worden afgevangen en doorgegeven aan de gebruiker.
Hier is een basisvoorbeeld van de T-SQL syntax voor het aanmaken van een stored procedure in SQL Server:
CREATE PROCEDURE ProcedureNaam
@Parameter1 DataType1 = DefaultWaarde1,
@Parameter2 DataType2
AS
BEGIN
— Procedure logica hier
SELECT * FROM TabelNaam WHERE KolomNaam = @Parameter1 AND AndereKolom = @Parameter2;
END;
Aandachtspunten:
- CREATE PROCEDURE ProcedureNaam: Hiermee start je de definitie van een nieuwe stored procedure met de naam ProcedureNaam.
- @Parameter1 DataType1 = DefaultWaarde1, @Parameter2 DataType2: Dit zijn de parameters die door de stored procedure worden geaccepteerd. @Parameter1 en @Parameter2 zijn de namen van de parameters, en DataType1 en DataType2 zijn de datatypes van deze parameters. Je kunt een standaardwaarde specificeren voor een parameter, zoals DefaultWaarde1 voor @Parameter1.
- AS BEGIN … END: Tussen BEGIN en END plaats je de T-SQL instructies die deel uitmaken van de stored procedure. Dit kan alles zijn van SELECT, INSERT, UPDATE, DELETE statements tot complexere logica.
Voorbeeld:
Hier is een concreet voorbeeld van een stored procedure die een lijst van klanten ophaalt op basis van een gegeven stad en een status:
Voorbeeld:
CREATE PROCEDURE HaalKlantenOp
@Stad NVARCHAR(100),
@Status BIT
AS
BEGIN
SELECT KlantID, Naam, Email FROM Klanten
WHERE Stad = @Stad AND Actief = @Status;
END;
In dit voorbeeld accepteert de stored procedure HaalKlantenOp twee parameters: @Stad (van het type NVARCHAR(100)) en @Status (van het type BIT, wat vaak wordt gebruikt voor booleaanse waarden zoals waar/niet waar of actief/inactief). De procedure voert een SELECT-operatie uit op de Klanten tabel en retourneert de rijen die overeenkomen met de opgegeven @Stad en @Status.
Het aanroepen van een Stored Procedure:
Je kunt de gecreëerde stored procedure aanroepen met de volgende syntax:
EXECUTE HaalKlantenOp @Stad = ‘Amsterdam’, @Status = 1;
Dit zal de HaalKlantenOp stored procedure uitvoeren met de gespecificeerde waarden voor de @Stad en @Status parameters.
Conclusie
Investeren in een goed databaseontwerp en levert op de lange termijn aanzienlijke voordelen op. Het zorgt niet alleen voor een goede informatiehuishouding die betrouwbaar is. Maar het zal zeker ook de ontwikkelstrategie van de organisatie op veel vlakken verbeteren. Daar waar de kwaliteit van informatie belangrijk is en ontwikkelteams zich kunnen richten op applicaties die functioneel zijn en gebruiksvriendelijk. Voor de dabasebeheerder is er een extra taak komen te liggen om de informatie centraal te stellen door een goede technische implementatie van het logische ontwerp. De basis is een goede gegevensanalyse door een informatieanalist of functioneel ontwerper die ver weg blijven van de onderliggende techniek.
Wanneer aan deze eisen wordt voldaan dan is er zeker sprake van:
- Prestatieverbetering: Een goed databaseontwerp optimaliseert de prestaties door efficiënte datatoegang en -verwerking mogelijk te maken, wat resulteert in snellere responstijden en een betere gebruikerservaring.
- Schaalbaarheid en Flexibiliteit: Kwalitatief ontwerp zorgt voor schaalbaarheid, waardoor databases kunnen groeien met de behoeften van het bedrijf zonder significante herontwerp- of onderhoudskosten.
- Data-integriteit en consistentie: Sterke databaserichtlijnen en constraints zorgen voor de integriteit en consistentie van gegevens, wat cruciaal is voor accurate rapportage, analyse en besluitvorming.
- Beveiliging: Door rekening te houden met beveiligingsaspecten in het ontwerpstadium, worden gegevens beter beschermd tegen ongeautoriseerde toegang en lekken.
- Onderhoud en Beheer: Een goed ontworpen database vereenvoudigt onderhoudstaken en maakt het beheer efficiënter, wat tijd en middelen bespaart.
- Compliance en Auditing: Goed ontwerp helpt bij het naleven van regelgeving en maakt auditingprocessen eenvoudiger door duidelijke datalogging en -tracking.